
让数据“听”得到
一、数据声音化的概念与用途
数据声音化(data sonification)是指将各类数据转换为人耳可感知的非语音声音的过程。简单来说,声音化利用声音这一媒介来“呈现”数据中的模式和信息,与我们常见的“数据可视化”相对应。通过设计合理的映射规则,数据的某些属性(如数值大小、变化趋势等)会对应到声音的属性(如音高、音量、音色、节奏),从而让听众通过听觉来理解数据。由于人类的听觉对节奏和音高变化非常敏感,声音化为科学研究和科普提供了一种直观而有趣的手段:它不仅能拓展数据分析的维度,在某些情况下帮助研究人员发现视觉难以察觉的细节模式,还能为公众体验科学现象提供全新的角度。
二、天文数据声音化的历史案例
盖革计数器:用“噼啪”声计数辐射
盖革-米勒计数器(Geiger-Müller Counter)可以看作最早的数据声音化装置之一。盖革计数器用于探测电离辐射,其原理是高能粒子进入充有稀薄惰性气体的探测管时引发气体电离,产生电流脉冲。传统的盖革计数器通常配有蜂鸣器,每当检测到一次放电就发出清脆的“咔哒”声。辐射越强,单位时间内脉冲越频繁,“咔哒”声就越急促。通过这种方式,无需盯着仪表盘上的读数,只要聆听盖革计数器的响声频率,就能直观判断辐射水平的高低。这一方法在核物理和宇宙线研究早期非常实用。
引力波的“啁啾”:LIGO的发现
2015年9月14日,美国激光干涉引力波天文台(LIGO)首次探测到了引力波信号GW150914,源自两颗黑洞并合。这一划时代的事件也伴随着人类首次“听见”宇宙引力波:当科研人员将探测器的时序数据转换为音频时,一个清晰上升的“啁啾”声(chirp)划过耳畔——低沉开始,频率和振幅迅速升高,在不足半秒内戛然而止。这正对应了理论预言的双黑洞螺旋并合信号特征:随着黑洞越旋越近,引力波频率从几十赫兹扫升至数百赫兹,振幅也在合并瞬间达到峰值。LIGO团队在科普视频中多次播放了这一引力波声音,将晦涩的信号以听觉方式呈现给公众。值得注意的是,引力波的本征频率本就在音频范围内(几十到上千赫兹),只需稍作处理(比如将频率上移到人耳较敏感的频段)即可直接听到。此后,LIGO和欧洲室女座(Virgo)探测到的每一次引力波事件几乎都被制成音频公开发布。通过对比不同事件的“声音”,人们可以直观感受双中子星并合的啁啾如何比黑洞并合更悠长尖锐,或者更大质量黑洞并合的声音如何更短促低沉等。这种听觉呈现不仅有助于科普,也被科学家用于分析:通过“听”引力波数据中的细节变化,辅助识别潜在信号。在这个意义上,引力波的声音化既是科学发现的副产物,更成为引力波天文学研究与传播中的标志符号。
NASA的天文图像声音化项目
钱德拉声音化项目由钱德拉X射线中心(CXC)主导,并得到NASA Universe of Learning计划的协助。他们将钱德拉X射线望远镜、哈勃太空望远镜和詹姆斯·韦伯望远镜等获得的实际天文观测数据,转换成能被人类耳朵感知的频率。由于数据特性和研究对象不同,每次“声音化”所使用的具体方法都不一样,旨在准确传达科学信息,并以声音创造新的感知和理解方式。项目从2020年开始持续运行。其宗旨最初是为了服务盲人和低视力群体,但很快发现声音化的产出对所有听众都充满吸引力,在全球媒体上广泛传播。该项目的声音化作品可以在A Universe of Sound、Hubble Sonification、JWST Sonification等站点找到。
项目中的声音化并非随意的音效拼凑,而是力求既忠实数据又具有审美体验。制作团队常常先将图像按照科学意义划分层次(如恒星、星云、背景等),分别设计映射方案,然后选择扫描路径(可以是从左到右、从上到下,或由中心向外辐射等)。这样的声音化作品既传达了图像的关键信息,又具有音乐性。
例如这张JWST拍摄的船底座星云宇宙悬崖的近红外图像,其映射方式为:图像的明亮程度对应声音的音量,垂直位置决定音高,较高位置的明亮区域音调较高,较低位置的明亮区域则音调较低;图像上半部分半透明的稀薄气体区域表现为嗡鸣风声,下半部分更密集的区域则更为清晰、富有旋律;星云中呈山脉状的密度变化区域用起伏的旋律线表达,而恒星则以处理过的钢琴音和亮星专属的钹声共同呈现,创造出一个富有层次感的声音景观,让人们通过听觉感受宇宙图像的丰富细节。
再比如蟹状星云的声音化,通过将不同波长的光线数据映射到特定的乐器来实现:钱德拉望远镜的X射线数据(蓝色与白色)被转译为铜管乐器的声音,哈勃望远镜的可见光数据(紫色)对应弦乐,而斯皮策望远镜的红外数据(粉色)则由木管乐器演奏。图像越靠上的区域音调越高,光线越明亮的区域声音也越响亮。
这些声音化作品发布后深受大众欢迎,也让许多视力正常的听众表示仿佛第一次“用耳朵看到了”宇宙。通过这一系列开创性实践,NASA证明了声音化在公众科普和包容性教育中的巨大潜力。
三、声音化的方法:从一维时间序列到二维频谱
一维数据通常是指随时间变化的信号或序列,例如恒星的光变曲线、引力波探测器的应变信号、射电望远镜的强度随时间变化曲线等。对这类数据进行声音化,有两种主要方式:
直接听波形(Audification):这是最直接的声音化方法,即将数据序列本身视作音频波形来播放。如果数据的采样率和频率内容落在人耳可闻的20 Hz–20 kHz范围内,那么直接将数据映射为扬声器振动即可“听到”原始信号。例如,LIGO的引力波应变数据采样率为4096 Hz,信号频率最高约数百赫兹,基本属于可听频段。因此LIGO团队在处理首个引力波事件GW150914时,直接将探测器输出加速播放并进行了轻微频移,使之落在人耳听觉最敏感的频率范围内,然后就得到了一段清晰可闻的引力波“啁啾”声。又如地震学中记录的地震波,其频率往往在每秒以下,但将地震波形整体提速1000倍播放,就可把不可闻的次声波变成几秒钟内可闻的一连串波动。
地震的声音(视频来自 Sonifyerorg) 这种方法本质上是对时间尺度或频率尺度进行线性拉伸/压缩,让原本听不见的超低频或超长过程变得可听可感。当然,直接听波形也有局限:如果信号中混杂噪声且信噪比较低,人耳可能难以从嘈杂的波形中分辨出细节。这时可以考虑对数据作预处理(如滤波、去趋势等)或结合可视化同时观看频谱,提高辨识度。此外,audification要求数据本身有一定连续性和足够采样点,对离散稀疏的数据就不适用了。
参数映射声音化(Parameter Mapping Sonification):这是目前应用最广泛的声音化技术。它不是直接播放原始数据波形,而是将数据的特征参数转换为声音的控制参数。例如,可以把一维数据序列视为一系列数据点事件,让每个数据点触发一个音符,其发生的时间和音高、音量由数据的属性决定。这正是Astronify等工具采用的方法。以恒星光变曲线为例,将恒星的亮度映射为频率,那么一颗变星亮度的起伏就会转变为一串高低起伏的音调。
Kepler_12b光变曲线通过astronify声音化 参数映射法的优点在于非常灵活:设计者可以有针对性地突出数据中关心的部分(通过映射选择),滤除不重要的信息,并赋予声音一定的艺术效果(例如选取悦耳的音阶,使声音化结果更美观易听)。这使其在科普演示中经常被采用,如NASA的图像声音化就是将图像特征参数映射成不同乐器音符的典型案例。
当数据具有二维结构时(例如频率-时间二维图、图像、光谱能量分布等),声音化的方法需要进一步拓展。典型情形之一是频谱随时间变化的二维数据,例如射电天文中的动态频谱,这在快速射电暴(FRB)和脉冲星研究中很常见,如下图所示。
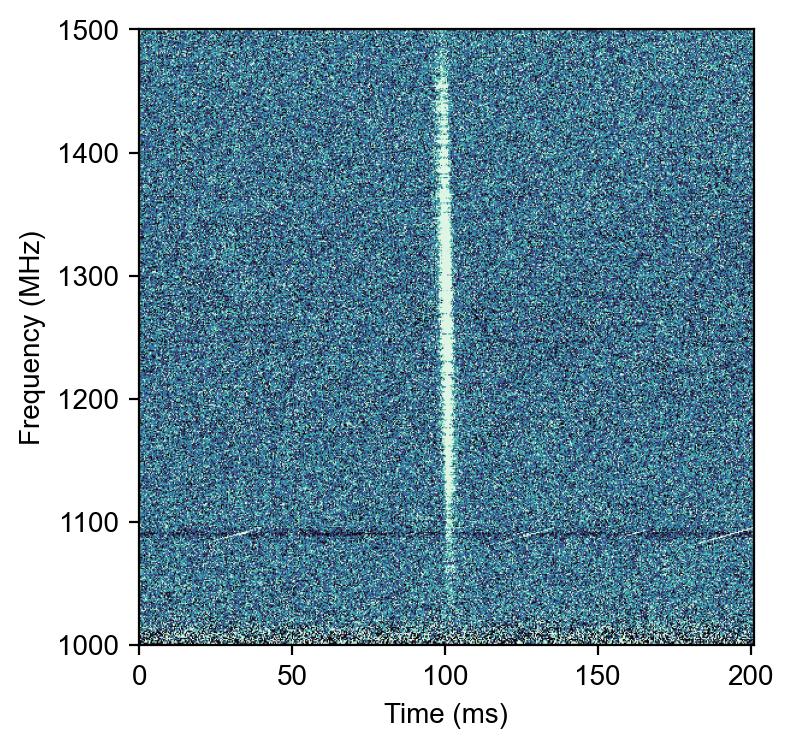
我们希望利用整张二维频谱信息来重建声音。这就类似于语音识别中的声谱图:语音的短时傅里叶变换可以得到时间-频率能量分布(spectrogram),反之要从spectrogram恢复语音,就需要推测出频谱在每个时刻的相位信息才能生成时域波形。射电数据的动态频谱本质上也是一个spectrogram(只是频率可能不是听觉频率,而是射电频率)。如果我们尝试将射电频谱图直接当作“声音的梅尔频谱”来处理,就面临相位缺失的问题:由于在记录数据时往往只保存各频率通道的强度,丢弃了信号的相位,我们无法直接还原出原始电磁波形。那么如何从二维频谱得到可听的波形呢?这就要用到**声码器(vocoder)**技术。
声码器原本指对语音进行编码和解码的技术装置,但在数字音频领域泛指从频谱或特征参数合成波形的方法。针对没有相位信息的频谱图,经典的解决方案是Griffin-Lim算法。该算法由D. Griffin和J. Lim于1983年提出,是一种迭代的傅里叶逆变换方法。其基本思路是:先随机猜测一组初始相位,与原始幅度谱组合后做傅里叶逆变换得到一个时间波形,再将该波形正变换回频谱以调整相位,反复迭代使重建波形的幅度谱逼近原始目标谱。直观来说,Griffin-Lim在频谱图上不断尝试“纠正”波形的相位,使之与已知幅度相匹配。经过若干次迭代后,通常就能合成出一段波形,使其频谱与输入的二维数据相符。Griffin-Lim算法实现简单、无需训练数据,因此常被用作频谱声音化的baseline方法。但其缺点是重建音质可能较为生硬、带有人工痕迹(例如金属噪音感)。
进入21世纪,随着深度学习的兴起,声音化频谱的声码器技术发生了革命性变化。特别是在语音合成(TTS)领域,诞生了一系列以神经网络生成波形的声码器模型。2016年,DeepMind提出了划时代的WaveNet模型。WaveNet是一个深层卷积神经网络,可以直接以逐采样方式生成原始音频波形。训练时,它以真实语音波形作为样本,学会了从条件输入(如梅尔频谱或文本隐表示)预测下一个音频采样点的分布,从而能够在给定梅尔声谱的条件下生成高度自然的语音。WaveNet证明了利用深度神经网络可以显著提升由频谱重建音频的质量,其生成的语音相比传统参数合成更加流畅、接近真人。但WaveNet的缺点是计算量大(逐点生成导致速度缓慢)。因此,研究者们又开发出多种改进的神经声码器以兼顾速度与质量:例如基于循环网络的WaveRNN,基于流模型的WaveGlow,基于生成对抗网络的MelGAN、HiFi-GAN等。其中HiFi-GAN(2020年提出)是目前应用广泛的高保真神经声码器之一。它采用GAN训练,使生成的波形在听觉上与真实录音难以区分,同时推理速度很快,可实时生成语音。不断涌现的最新模型如BigVGAN(2023)在此基础上进一步提升了合成质量和对多说话人、多音色的兼容性。总的来看,神经声码器的发展经历了从Autoregressive模型(如WaveNet逐点生成)到非自回归模型(如GAN并行生成)的演进,大幅拓展了机器从频谱“想象”声音的能力。
四、射电数据声音化
为了将上述方法付诸实践,我们开发了一个射电数据声音化项目工具,并利用该工具对FAST望远镜的观测数据进行了声音化尝试。项目开源代码托管在 GitHub SukiYume/MSP(Methods for Sonifying Pulsar data)库中,其设计初衷是探索射电脉冲星及快速射电暴数据的多种声音化方案。包括
方法1:直接波形写入 – 将脉冲星平均脉冲轮廓视为音频波形,直接等间隔重复拼接写入WAV音频。简单而言,即把每次脉冲当作声音波形的一段,通过适当插值或卷积使其成为可播的连续音频。这种方法产生的声音听起来像一系列有规律的敲击。如果各个脉冲轮廓形状相似,直接写入的声音不同数据之间差别不大。因此我们尝试将脉冲信号与一些乐器声音进行卷积叠加,赋予不同脉冲星“不同音色”,以增强可辨识度。
方法2:振幅调制映射 – 将脉冲轮廓映射为现成音频的音量包络。具体做法是选取一种连续声音(例如持续的底噪或合成音),然后用脉冲星信号的强度随时间变化来调制这个声音的音量大小。这样当脉冲强时原声音量大,脉冲弱时声音轻,从而把脉冲信号“刻画”在背景音中。
方法3:频谱声码器重建 – 利用Griffin-Lim算法和深度学习声码器对射电动态频谱进行重建。我们对于每一段观测,先对动态频谱进行必要的射频干扰滤波和去色散校正,然后将其视作梅尔频谱输入声码器。传统方式下,我们使用Griffin-Lim迭代法重建初步音频;在深度学习方式下,我们使用了HiFi-GAN声码器模型进行重建。具体而言,我们选用公开的HiFi-GAN Universal V1预训练模型,并额外用500首交响乐曲目对其做了继续训练(fine-tune)以增强其合成音乐音效的能力。这款微调后的模型被用于将射电频谱转换为音频,其输出的声音质量令人满意:脉冲信号清晰,底噪得到了较好的抑制,听感相比Griffin-Lim结果更自然。
利用这种方法,我们生成了一系列FAST射电数据的声音化示例,并将结果发布在一个在线笔记中。听众可以通过点击相应图像来收听对应的声音,每个图像都展示了该声音对应的数据内容。例如
纯背景噪声:选取了一段没有天体信号只有射电干扰的观测数据。从频谱图上可以看到,人为射电干扰在特定频段呈现明暗相间的条纹,可以在音频中明显听出。
脉冲星信号:我们选取了几颗不同周期的射电脉冲星观测数据,将其经过消色散后的动态频谱进行声音化。从频谱图可以看出,消色散后,脉冲同时出现为竖条纹。将其声音化后,每颗脉冲星都发出规律的“跳动”声,类似节拍器按照其自转周期在敲击。
我们还尝试了不经过色散校正直接声音化的效果:此时频谱图上脉冲呈现出频率越高到达越早的倾斜曲线,而声音则表现为每次脉冲从高音滑落到低音的扫频声,非常有趣。
五、结语
数据声音化为理解和传播天文学打开了一扇独特的窗户。对于科研而言,声音化与可视化形成了互补:视觉善于同时呈现空间细节,听觉则擅长捕捉时间节奏和微弱变化,将两者结合可以实现对数据更全面的感知。对于公众科普而言,声音化提供了一种充满魅力的传播形式。一段黑洞并合的啁啾、一曲星云图像谱写的乐章,比起晦涩的论文和冰冷的曲线,更能激发好奇心和想象力。这不仅拓展了科学的受众边界,也在某种程度上丰富了人类感知宇宙的方式。